In this post, I want to walk through a classic problem in aerodynamics — wing shape optimization — through the lens of a modern technique in optimal experimental design called Bayesian optimization (BO).
I want to do this because, looking back to when I was in undergrad, I wished I'd had access more computer models that strike a "Goldilocks" balance of being complex enough to be relevant to real aerospace design, but still stimple enough that only a modest amount of effort is required to tinker with them.
I'm guessing a lot of folks who are early in their engineering journey feel similarly, and so I'd like to try and provide such a problem here.
I'm hoping this'll be useful to anyone who wants an accessible entry point into the intersection of aerodynamics, uncertainty quantification, and optimization.
I'll describe the problem first, then talk about the physics solver we'll use to model the aerodynamics, then talk about the method we'll use for shape optimization, and then we'll put all the pieces together.
As a heads-up, I'll only be giving a brief intro to both panel methods and Bayesian optimization; just the bare minimum to understand the core ideas.
I'd encourage anyone who's interested in learning more to glance at the references I've linked at the end, or just poke around the web.
The problem: airfoil shape optimization
Let's wax philosophical: engineering is all about compromises.
The structural elements of an airplane need to be strong enough so that the wings don't break off and you fall out of the sky.
That would seem to suggest that we should build them out of a really strong material like steel, except that steel is really heavy, which is not great for the main objective of getting up into the sky in the first place. This is why we use composites that are not as strong as steel, but strong enough, and far lighter.
Compromises!
A nice starting point for thinking about these sorts of things is the trade-offs between structural and aerodynamic considerations in wing design.
So let's imagine this: you are a brand new aerospace engineer (congratulations).
For your first project, you're told that the company is looking to design a new wing concept.
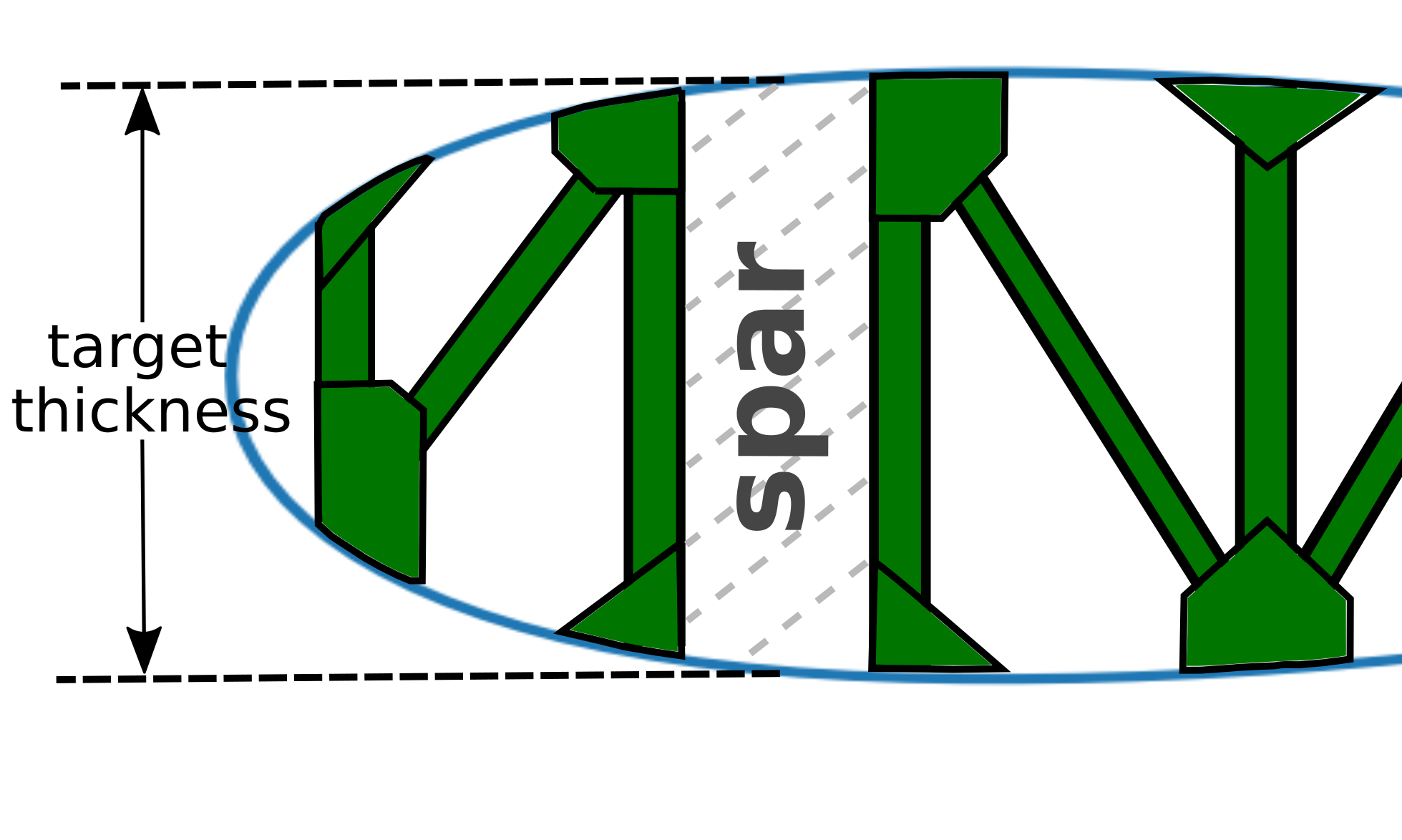
It needs to have a certain thickness at the quarter-chord, in order to allow for a sufficiently large spar.
At the same time, there are desired aerodynamic properties that need to be maintained in trim flight conditions.
Desired structure (airfoil thickness).
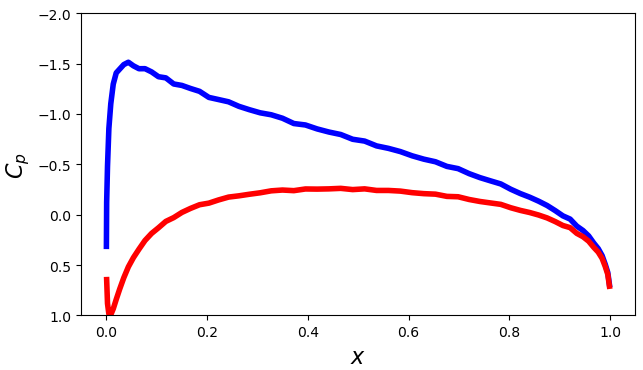
Desired aerodynamics (pressure distribution).
So, you'll need to find the airfoil shape that best satisfies both objectives simultaneously.
You want to use computer simulations or experiments to find the best answer, but these are time-consuming, or expensive, or just plain hard to do — meaning you can't just "brute force" your way to an answer.
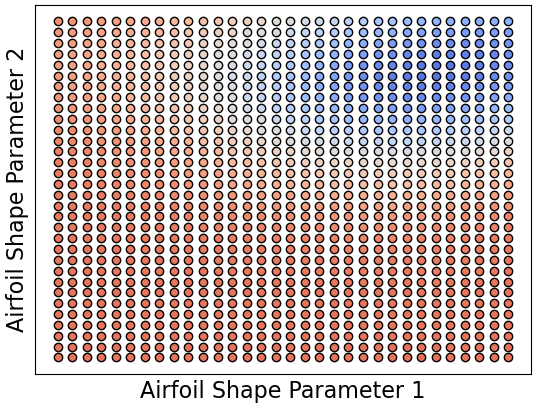
Design strategy #1: "grid up" the entire parameter space and test every single point. Not cool feasible.
Design strategy #2: use surrogate models to intelligently guide a sequence of samples. Very cool feasible.
In other words, we're looking to avoid the left picture, and instead do something resembling the right one, where we test airfoil shapes in an intelligent way that balances exploring the parameter space with exploiting information from previous samples that seem close to an optimum.
We want to quickly "rule out" regions of the parameter space that are unlikely to contain the optimal design, and "hone in" as quickly as possible on those areas that are likely to contain it.
So we need to vary the airfoil shape. How do we do that?
It's important to discuss this up-front because the dimensionality of the parameter space could dictate what methods are available to us for optimization.
If you were to discretize an airfoil into a set of, say, 100 points in the 2-d plane, and then consider all possible airfoils constructed by independent variations of those 100 points, then you would be optimizing over a 100 dimensional parameter space.
This is not the kind of place you should prefer to be in (though in some problems, you may not have a choice!).
This begs the question: can we avoid being in such a setting?
Speaking generally, the problem of how to "compress" a space of enormous dimension into a much smaller one without significant loss of information is what the field of low-dimensional modeling is all about.
This is near and dear to my heart, but also a vast subject that it deserves its own blog post (coming soon, probably).
For this problem, the good news is, there already exist fairly low-dimensional parameterizations of airfoil shapes that we can just use directly.
One such parameterization (thanks to this guy) nicely compresses symmetric airfoil shapes into 2 parameters that govern the maximum airfoil thickness:
This equation definitely does not win any prizes for mathematical beauty, but it is convenient.
The parameters are: \(m\), the location of maximum thickness, and \(T\), the maximum thickness (the \(a_i,d_i\) are functions of \(m,T\)).
This is the space of admissible airfoils we will consider.
Below are some examples of the sorts of shapes you can get.
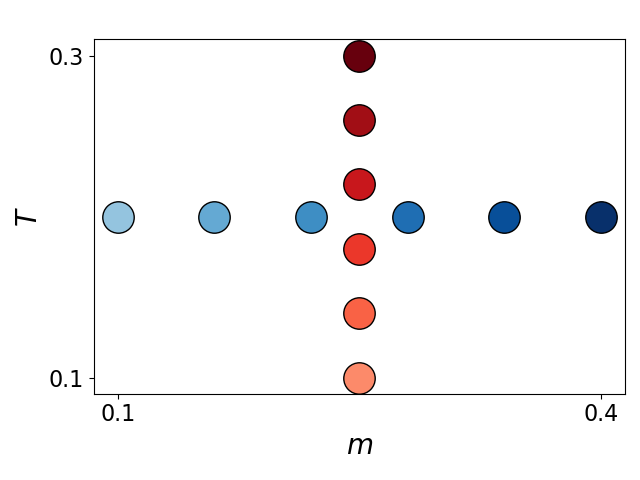
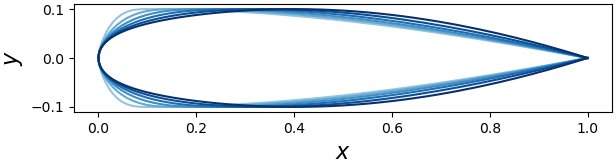
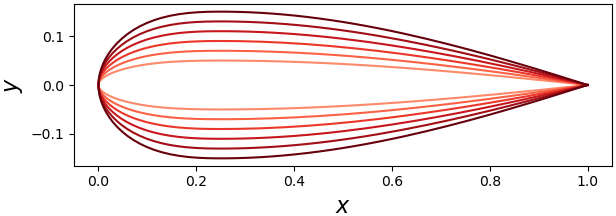
Parameter space. Color of points is one-to-one with corresponding shapes to the right.
Variation in \(m\).Variation in \(T\).
Computing the aerodynamics: panel methods
Alright, so we have a parameter space to explore. Let's talk about how we compute a value for a given point in that space.
For this problem, we'll use something called a panel method to compute the pressure distribution for a given airfoil.
Panel methods, or potential flow solvers, are a way of approximating the solution to Laplace's equation:
\[ \nabla^2 \phi = 0 \]
Here, \(\phi(\mathbf{x})\) is a potential field at a given spatial location.
Fluid flows are, of course, governed at the continuum level by Navier-Stokes.
However! If one assumes the flow to be (1) inviscid, (2) irrotational, (3) incompressible, and (4) steady-state, then these equations effectively reduce to Laplace's equation, and the fluid velocity can be derived directly from a potential field.
For boundary conditions, we constrain the airfoil surface to be a streamline of the flow.
This is equivalent to saying that the potential should not vary in the direction normal to the surface \(\mathbf{x}_{\mathcal{S}}\) of the airfoil:
\[ \frac{\partial \phi( \mathbf{x}_{\mathcal{S}} )}{\partial \hat{u}_n} = 0 \]
The Laplace equation is linear and homogeneous, which means we are free to construct solutions to it using a superposition of Green's functions of the \(\nabla^2(\cdot)\) operator.
One must take care in choosing these elements, and additionally in enforcing an effective Kutta condition (or else the solution will have zero lift), but that's essentially it.
If that was too mathy, the brass-tacks version goes as follows.
We first cover the airfoil surface in panels, where each panel exerts an influence on the value of the potential \(\phi(\mathbf{x})\) at any point \(\mathbf{x}\).
At the center point of each panel, we demand that the total potential influence exerted by all panels sum to satisfy the zero-normal flow boundary condition.
If we have \(N\) panels, then this gives us a system of \(N\) linear equations to assemble and solve.
Solving the system yields the potential \(\phi(\mathbf{x}_{\mathcal{S}})\), which can be differentiated to find the surface pressure distribution.
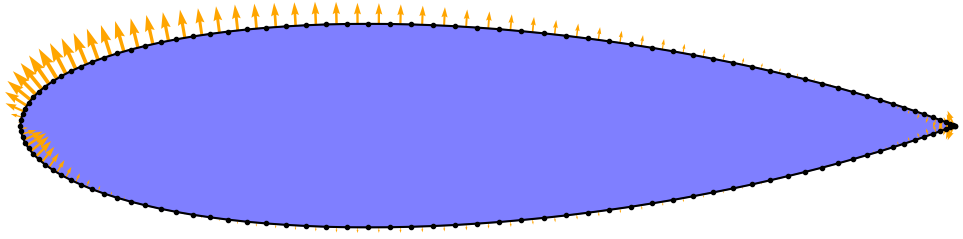
Example pressure distribution computed with panel method (local pressure is proportional to arrow length).
Now, let's address this: it may be objected that inviscid, irrotational, incompressible, steady-state flows don't really exist; certainly not on airplanes.
Is that true? Yup! They don't. Does this impose limitations on what panel methods can actually model? Yup! Panel methods don't predict viscous drag, stall, or other phenomena involving viscosity and high-speed aerodynamics.
Does this mean we should throw them in the trash? No! Panel methods have a long and successful history in low-speed applications for smooth airfoils at modest angles-of-attack.
And, compared to modern tools in computational fluid dynamics (CFD), they're relatively easy to code, and run very fast.
For these reasons, they're great, both as a starting point for building interest in CFD and as an accessible sandbox for optimization algorithms.
In terms of software implementation: I'll be using a legacy solver written in Fortran by seminal researchers in the field.
You can find a Github repo containing it here.
You may have to make slight alterations for input/output purposes, but otherwise it should compile and run fine.
I've considered re-writing it in C++ and/or Python for maintainability/pedagogical purposes, but haven't gotten around to it just yet; if I do, I'll be sure to come back and link it here.
Solving the problem efficiently: Bayesian optimization
BO demo. An unknown function is approximated by a Gaussian process, whose mean (left) and variance (right) evolve as more samples are chosen. Notice how the method balances exploring new regions of parameter space which have high uncertainty (variance) with exploiting pre-existing knowledge of the location of minima.
Now, we finally get to the question of how to solve the optimization problem.
In this post, we'll approach this with Bayesian optimization (BO).
I'm showing above an example of BO on a function that I made up, so that you can get an intuition for what it's doing.
The goal is to find the global minimum of this function as quickly as possible.
We start with random sample evaluations, given by the green 'x' marks.
The left figure shows our (average) estimate of the unknown function (using a technique we'll talk about in this section), and the right figure shows our uncertainty about our predictions at those values.
The movie shows the evolution of both as we add more sample evaluations.
Two things should be apparent:
(1) BO adds samples in a way that balances checking-out new areas of parameter space (exploration) with "honing-in" around our current estimates of the minimum (exploitation),
(2) as the number of samples increases, our uncertainty tends to decrease everywhere, until we are highly certain of our predictions.
Following convention in the field, we'll write the general optimization problem as a maximization problem (though the same ideas apply if we'd like to minimize a function):
\[ \mathbf{x}^* = \text{argmax}_{\mathbf{x} \in X} [f(\mathbf{x})] \]
In BO, we want to construct a surrogate that interpolates/extrapolates \(f(\mathbf{x})\) at unseen values of \(\mathbf{x}\), and use this approximation to (1) estimate the optimizer \(\mathbf{x}^*\) and (2) suggest (intelligently!) new locations to sample.
We begin by plunking down an initial set of a few samples in parameter space:
\[ X_0 = \lbrace \mathbf{x}_1 , \dots , \mathbf{x}_k \rbrace \;\; , \;\; F_0 = \lbrace f(\mathbf{x}_1) , \dots , f(\mathbf{x}_k) \rbrace\]
The surrogate we construct is a particular type of stochastic process, called a Gaussian process (GP).
When using a GP, we make the assumption that probability that we observed the outputs \(F_0\) at inputs \(X_0\) is normally-distributed about a pre-specified mean function, \(m(\mathbf{x})\), and covariance function or kernel, \(\sigma(\mathbf{x},\mathbf{x}')\):
\[ p(F_0|X_0) = \text{Normal}( F_0 | \boldsymbol{\mu_0} , \Sigma_0 ) \]
Here, \(\boldsymbol{\mu_0} = [ m(\mathbf{x}_1) , \dots , m(\mathbf{x}_k) ]\) is the vector of mean evaluations at the data points, and \([\Sigma_0]_{i,j} = \sigma(\mathbf{x}_i , \mathbf{x}_j)\) is the data covariance matrix.
In order to interpolate/extrapolate, one can derive from this a posterior prediction at an unseen data point \(\mathbf{x}_{\text{new}}\), i.e. \( p(f_{\text{new}}|\mathbf{x}_{\text{new}},X_0,F_0) \), which will again be normally-distributed:
\[ p(f_{\text{new}}|\mathbf{x}_{\text{new}},X_0,F_0) = \text{Normal}( f_{\text{new}} | \mu_{\text{new}} , \sigma_{\text{new}} )\]
Here, \(\mu_{\text{new}}\) and \(\sigma_{\text{new}}\) are simply posterior estimates of the mean and variance at point \(\mathbf{x}_{\text{new}}\).
I don't want to go too far into the weeds, so I'm going to omit the details of how one may compute these quantities.
But the bottom-line is this: with some sample points, we can construct a GP surrogate from that data that approximates function values everywhere in parameter space, and provides uncertainty estimates at those locations.
As we collect more data points, this GP model can be updated, giving a (hopefully better) estimate of the true function \(f(\mathbf{x})\).
Returning to BO, the last major question is: how do we determine where to put the new samples in order to do that?
A popular method for doing this is by using an acquisition function called the expected improvement.
The intuition goes like this.
Say after \(k\) sample points, \(\mathbf{x}_1 \dots \mathbf{x}_k\), our GP estimate of the function maximum is \(f^*_k\).
We'd like to choose for our next sample the one that we expect will give us the largest improvement on the \(f^*_k\).
We obviously don't know the function value until we evaluate it, but we can estimate this quantity using our current GP surrogate.
Mathematically, we can write this as an expectation maximization:
\[ \mathbf{x}_{k+1} = \text{argmax}_{\mathbf{x} \in X} [ \text{EI}(\mathbf{x}) ] \]
\[ \text{EI}(\mathbf{x}) = \mathbb{E}_k[ \text{max}( f(\mathbf{x}) - f^*_k , 0 ) ] \]
Here, the \(\mathbb{E}_k[\cdot]\) indicates that the expectation is taken over the current GP surrogate constructed using our \(k\) sample points.
The \(\text{EI}(\mathbf{x})\) may be evaluated analytically for a GP model, but again, I won't get into the details for that here.
And that, in a nutshell, is BO!
Regarding software, the great news is that BO is supported by lots of libraries in popular languages.
I'll be using Python's Scikit Optimize, in particular this, which makes "vanilla" BO very easy to use with arbitrary user-defined functions.
All you really have to do is write a Python function to compute the cost of a given airfoil by wrapping calls to the underlying Fortran panel code solver.
Once done, you can pass this Python function to \(\text{skopt.gp_minimize}\).
If you know some Python, it should be a breeze.
Results
At this point, we have all the tools needed to tackle the airfoil optimization problem.
The optimization problem I'll consider is this:
\[ J(m,T) = 1 - \text{exp}\left( -\frac{1}{2\sigma_1^2} ( z_{c/4}(m,T) - z_{c/4}^* )^2 \right) \text{exp}\left( -\frac{1}{2\sigma_2^2} \|C_P(x;m,T) - C_P^*(x) \|^2 \right) \]
Here, \((m,T)\) are the pair of airfoil shape parameters discussed earlier, \(z_{c/4}\) denotes the airfoil thickness at quarter-chord, and \(C_P(x)\) denotes the pressure distribution (computed at a trim angle-of-attack of \(\alpha=5^\circ\)) as a function of chordwise-distance.
\(z_{c/4}^*\) and \(C_P^*(x)\) are our target thickness and pressure distributions, respectively.
Let's first check out the performance of our BO routine:
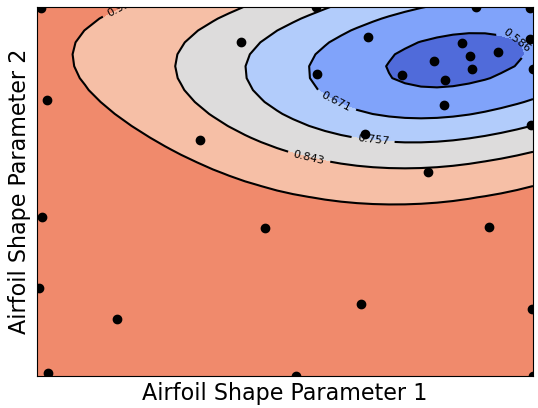
BO results with GP mean (left) and variance (right).
It appears that after just 32 samples, the GP mean has "crystallized" with relatively low variance.
We see the clear presence of a global minimum in the upper-right corner.
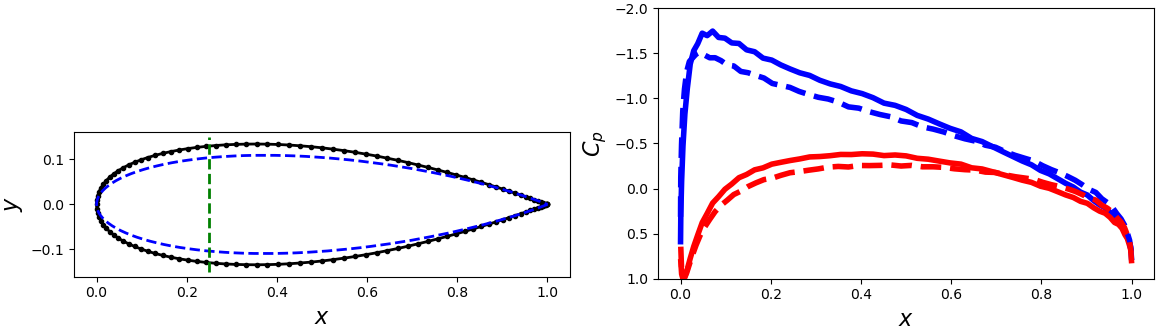
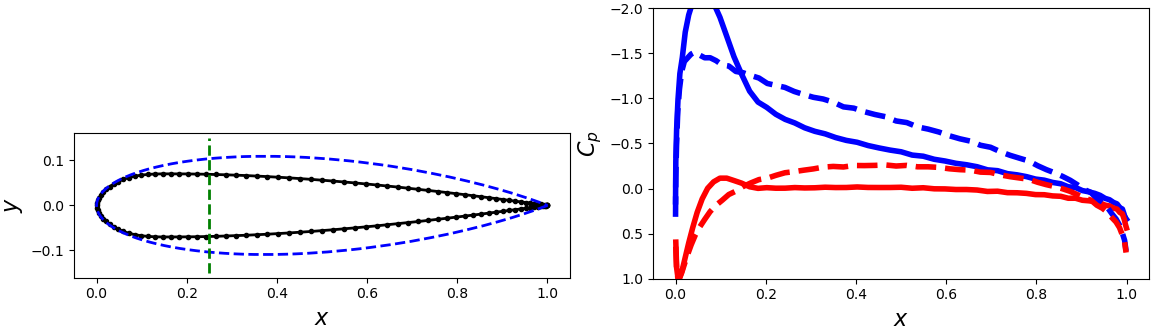
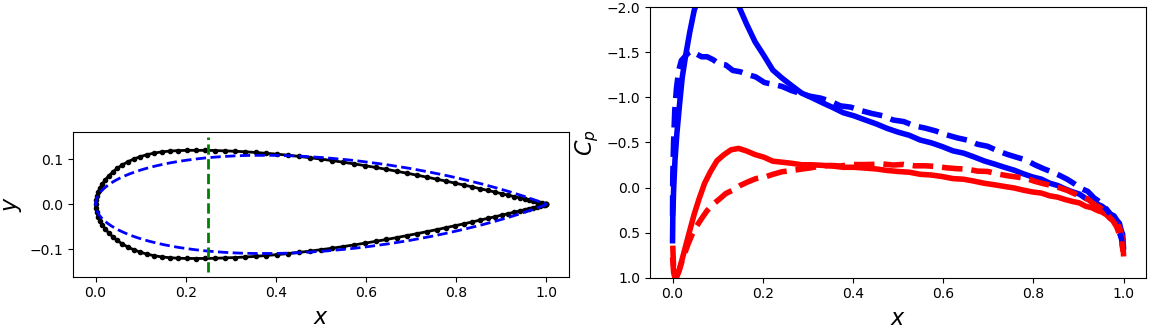
Let's look at this optimal solution, and compare it to some other solutions.
In the first column, I'm displaying the wing for a given \((m,T)\) combination in black.
The dashed blue is a "base" airfoil (not chosen from the \((m,T)\) parameter space) that was used to generate the target pressure distribution.
The dashed green line is the target quarter-chord thickness.
In the second column, I'm showing the computed pressure distribution for the top (blue) and bottom (red) airfoil surfaces, compared to the target pressure distribution (dashed).
And sure enough, we can see that the computed optimum does a far better job balancing the two goals than the others: the sample at \((0.16,0.14)\) is far too thin, and the pressure distribution is off by quite a bit; \((0.22,0.24)\) is much better for the target thickness, but still the pressure distribution is very wrong.
And that's it.
Hopefully it's been fun to read, but above all, I hope this inspires you to get out and tinker!
That really is the best way to learn this stuff.
References
Frazier, Peter I. "A tutorial on Bayesian optimization." arXiv preprint arXiv:1807.02811 (2018).
Williams, Christopher KI, and Carl Edward Rasmussen. "Gaussian processes for machine learning." Vol. 2. No. 3. Cambridge, MA: MIT press, 2006.
Katz, Joseph, and Allen Plotkin. "Low-speed aerodynamics." Vol. 13. Cambridge university press, 2001.